HDFS(Hadoop Distributed File System):
HDFS is a distributed file system, It's specially design for storing huge data set with cluster(group of hardware) of commodity hardware through streaming access pattern. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardwares.
Streaming access pattern -> "write once , read n number of times but don't change content of file".
Hadoop daemons:
Hadoop 1.0
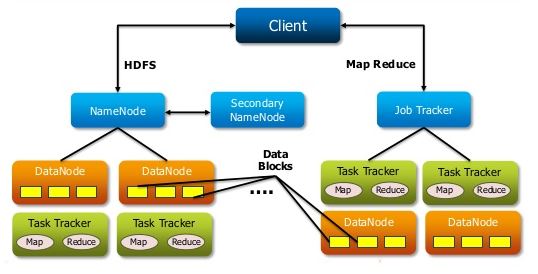
Master- NameNode, JobTracker, Secondary NameNode,
Slave- DataNode, TaskTracker
Hadoop 2.0
Master - NameNode, Secondary NameNode, Resource Manager
Slave - DataNode, Node manager.
IMP: To store data what are the services we need:- NameNode(to create metadata), DataNode(to store actual data).
IMP: To process data:- JobTracker and TaskTracker.
Single Point of failure:
Hadoop 1.0:- The NameNode is the single point of failure. Each cluster has a single NameNode and if that machine is not available, the whole cluster will not be available.
Hadoop 2.0:- HDFS comes with high availability which overcome the single point of failure by providing an option to run two NameNodes in the same cluster as an Active/Passive configuration with a hot standby.

NameNode and DataNode:
HDFS has the NameNode and DataNode as known as Master/Slave. The NameNode contains Metadata and perform operations like opening, closing, and renaming files and directories. The DataNode is responsible for serving request from client's system. It also performs block creation, deletion, and replication upon instruction from the NameNode. HDFS is built using java language and because of java portability, it can deployed/run on wide range of machines.
Data Replication:
HDFS is designed to store large volume of data across machines in a large cluster. It stores each files as a sequence of blocks and the blocks of files are replicated to overcome with fault-tolerance. We can set the block size and the replication factor manually by changing in hdfs-site.xml file which usually found in the conf/ folder of the Hadoop installation directory. Once you are in the conf/ folder, find the below properties to make any change in that.
<property>
<name>dfs.replication<name>
<value>3<value>
<description>Block Replication<description>
<property>
hdfs-site.xml is used to configure the HDFS and any changes made in this file would be default replication for all the files placed in HDFS. We can perform replication factor on a per file basis also by using the below shell command.
> hdfs dfs -setrep -w 2 /user/cloudera/training/userdata.txt [This shell command will set the replication 2 for the file userdata.txt]
IMP: What is the default replication factor(default value in HDFS) -> 3 which means for each block stored in HDFS will have 1 original block and 2 replicas.
Architecture:

Block size in HDFS:
The default block size in Hadoop 2.0 is 128MB and earlier it was 64MB for the Hadoop 1.0, This is used to divide the input file into blocks and distribute those blocks across the cluster. For example: if the input file size is 170MB which is put into HDFS and the default block size in Hadoop 2.0 is 128MB then, HDFS would split the file into 2 blocks which would be as of 128MB each. The first block will have 128MB and the other block will have 42MB space(Remaining space will be available for OS which is 86MB).
If we want to change the default size of block in HDFS so it can be via hdfs-site.xml. It will change the default block size for all the files placed into HDFS.
<property>
<name>dfs.block.size<name>
<value>134217728<value>
<description>Block size<description>
<property>
IMP: Changing the block size in HDFS will not affect any files currently available in HDFS, it will only affect the file which is placed after the setting has taken effect.
IMP: Why 128mb of block size, why not 128kb of block size-> For each block in HDFS , we need to create metadata in namenode so if we go with 128kb of block size then it will have to create more metadata for every blocks.
Metadata:
What do you means by Metadata ? . It's the additional information about our data, Like - Number of input splits, number of replication, data block location, file size etc. HDFS namespace is stored by the NameNode. The NameNode uses a transaction log called EditLog to keep update the record when every change occur in the files system.
There are 2 importaint files:
1. FsImage
2. EditLog
HDFS is a distributed file system, It's specially design for storing huge data set with cluster(group of hardware) of commodity hardware through streaming access pattern. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardwares.
Streaming access pattern -> "write once , read n number of times but don't change content of file".
Hadoop daemons:
Hadoop 1.0
Master- NameNode, JobTracker, Secondary NameNode,
Slave- DataNode, TaskTracker
Hadoop 2.0
Master - NameNode, Secondary NameNode, Resource Manager
Slave - DataNode, Node manager.
IMP: To store data what are the services we need:- NameNode(to create metadata), DataNode(to store actual data).
IMP: To process data:- JobTracker and TaskTracker.
Single Point of failure:
Hadoop 1.0:- The NameNode is the single point of failure. Each cluster has a single NameNode and if that machine is not available, the whole cluster will not be available.

Hadoop 2.0:- HDFS comes with high availability which overcome the single point of failure by providing an option to run two NameNodes in the same cluster as an Active/Passive configuration with a hot standby.

NameNode and DataNode:
HDFS has the NameNode and DataNode as known as Master/Slave. The NameNode contains Metadata and perform operations like opening, closing, and renaming files and directories. The DataNode is responsible for serving request from client's system. It also performs block creation, deletion, and replication upon instruction from the NameNode. HDFS is built using java language and because of java portability, it can deployed/run on wide range of machines.
Data Replication:
HDFS is designed to store large volume of data across machines in a large cluster. It stores each files as a sequence of blocks and the blocks of files are replicated to overcome with fault-tolerance. We can set the block size and the replication factor manually by changing in hdfs-site.xml file which usually found in the conf/ folder of the Hadoop installation directory. Once you are in the conf/ folder, find the below properties to make any change in that.
<property>
<name>dfs.replication<name>
<value>3<value>
<description>Block Replication<description>
<property>
hdfs-site.xml is used to configure the HDFS and any changes made in this file would be default replication for all the files placed in HDFS. We can perform replication factor on a per file basis also by using the below shell command.
> hdfs dfs -setrep -w 2 /user/cloudera/training/userdata.txt [This shell command will set the replication 2 for the file userdata.txt]
IMP: What is the default replication factor(default value in HDFS) -> 3 which means for each block stored in HDFS will have 1 original block and 2 replicas.
Architecture:

Block size in HDFS:
The default block size in Hadoop 2.0 is 128MB and earlier it was 64MB for the Hadoop 1.0, This is used to divide the input file into blocks and distribute those blocks across the cluster. For example: if the input file size is 170MB which is put into HDFS and the default block size in Hadoop 2.0 is 128MB then, HDFS would split the file into 2 blocks which would be as of 128MB each. The first block will have 128MB and the other block will have 42MB space(Remaining space will be available for OS which is 86MB).
If we want to change the default size of block in HDFS so it can be via hdfs-site.xml. It will change the default block size for all the files placed into HDFS.
<property>
<name>dfs.block.size<name>
<value>134217728<value>
<description>Block size<description>
<property>
IMP: Changing the block size in HDFS will not affect any files currently available in HDFS, it will only affect the file which is placed after the setting has taken effect.
IMP: Why 128mb of block size, why not 128kb of block size-> For each block in HDFS , we need to create metadata in namenode so if we go with 128kb of block size then it will have to create more metadata for every blocks.
Metadata:
What do you means by Metadata ? . It's the additional information about our data, Like - Number of input splits, number of replication, data block location, file size etc. HDFS namespace is stored by the NameNode. The NameNode uses a transaction log called EditLog to keep update the record when every change occur in the files system.
There are 2 importaint files:
1. FsImage
2. EditLog
Metadata is kept on highly configured system as NameNode, It keeps an image of entire file system through FsImage and EditLog transactions. The FsImage would have data of a file from pre one hour data to its started execution time whereas EditLog has the latest one hour data.
When the NameNode starts up, it reads the FsImage and EditLog from the disk. All the latest data flushes out from EditLog to FsImage and It can truncate the old EditLog because the transactions has been applied to FsImage. This process is called Checkpoints.
Data Node stores HDFS file in its local file system and doesn't have any knowledge about HDFS files. It stores HDFS files in separate local file system to overcome with data loss. Data Node keeps sending Heartbeat to NameNode after specific time interval. It scans through its local file system, generates a list of all HDFS data blocks that correspond to each of these local files and sends this report to the NameNode: which is known as Blockreport.
Difference between Hadoop 1 vs Hadoop 2:
The biggest difference between both is YARN technology. YARN stands for Yet Another Resource Negotiator. YARN has 2 daemons which take care of 2 tasks - JobTrackera and TaskTracker.
In Hadoop 2.0, JobTracker and TaskTracker has been replace by Resource Manager and Node Manager.
Resource Manager: It allocates resources to various applications.
Node Manager: It monitors the execution of the process.


No comments:
Post a Comment