
Question.
How can you apply the data to the warehouse? What are the modes?
Answer:
Data may be applied in the following four different modes: load, append, destructive merge, and constructive merge. Let us understanding of the effect of applying data in each of these four modes:
Load: If the target table to be loaded already exists and data exists in the table, the load process wipes out the existing data and applies the data from the incoming file. If the table is already empty before loading, the load process simply applies the data from the incoming file.
Append:You may think of the append as an extension of the load. If data already exists in the table, the append process unconditionally adds the incoming data, preserving the existing data in the target table. When an incoming record is a duplicate of an already existing record, you may define how to handle an incoming duplicate. The incoming record may be allowed to be added as a duplicate. In the other option, the incoming duplicate record may be rejected during the append process.
Destructive Merge : Merge In this mode, you apply the incoming data to the target data. If the primary key of an incoming record matches with the key of an existing record, update the matching target record. If the incoming record is a new record without a match with any existing record, add the incoming record to the target table.
Constructive Merge: This mode is slightly different from the destructive merge. If the primary key of an incoming record matches with the key of an existing record, leave the existing record, add the incoming record, and mark the added record as superseding the old record.
Answer:
Data may be applied in the following four different modes: load, append, destructive merge, and constructive merge. Let us understanding of the effect of applying data in each of these four modes:
Load: If the target table to be loaded already exists and data exists in the table, the load process wipes out the existing data and applies the data from the incoming file. If the table is already empty before loading, the load process simply applies the data from the incoming file.
Append:You may think of the append as an extension of the load. If data already exists in the table, the append process unconditionally adds the incoming data, preserving the existing data in the target table. When an incoming record is a duplicate of an already existing record, you may define how to handle an incoming duplicate. The incoming record may be allowed to be added as a duplicate. In the other option, the incoming duplicate record may be rejected during the append process.
Destructive Merge : Merge In this mode, you apply the incoming data to the target data. If the primary key of an incoming record matches with the key of an existing record, update the matching target record. If the incoming record is a new record without a match with any existing record, add the incoming record to the target table.
Constructive Merge: This mode is slightly different from the destructive merge. If the primary key of an incoming record matches with the key of an existing record, leave the existing record, add the incoming record, and mark the added record as superseding the old record.
Question.
Let's say that the data warehouse for Big_University consists of four dimension students, courses, semesters and trainers, and there are two measurements and avg_grade. At the lowest ideological level (eg, for a given student, curriculum, semester and trainer combination), avg_grade measures the student's actual course grade. At higher conceptual levels, avg_grade stores the average grade for the given combination. Draw a snowflake schema diagram.
Answer:
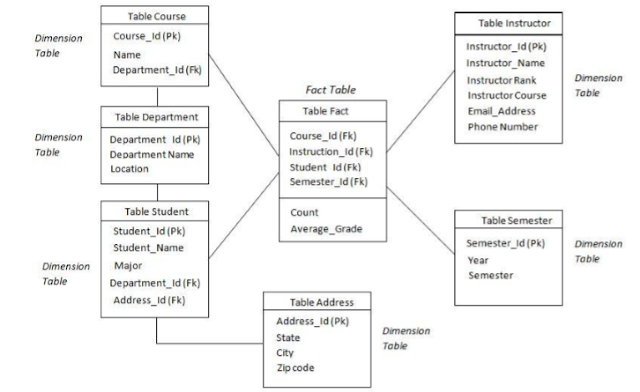
Question.
Based on current trends in technology need to design information systems . Explain the points to be taken care with respective traditional operational systems and the newer informational systems that need to be built?
Answer:
The essential reason for the lack of ability to provide strategic facts is that we have been trying all along to provide strategic facts from the operational systems. These operational systems such as command processing, record control, dues and claims processing, casualty billing, and so on are not planned or intended to deliver strategic information. If we need the skill to provide strategic data and information, we must get the information from overall different types of systems. Specially designed decision care systems or informational systems can deliver strategic information.
We find that in order to provide strategic information we need to build informational systems that are different from the operational systems we have been building to run the basic business. It will be worthless to continue to dip into the operational systems for strategic information as we have been doing in the past. As companies face fiercer competition and businesses become more complex, continuing the past practices will only lead to disaster.- Watching the wheels of business turn
- Show me the top-selling products
- Show me the problem regions
- Tell me why (drill down)
- Let me see other data (drill across)
- Show the highest margins
- Alert me when a district sells below target

We need to design and build informational systems
- That serve different purposes
- Whose scopes are different
- Whose data content is different
- Where the data usage patterns are different
- Where the data access types are different
Question.
2-D data pulled out from the data cube.
Product ID | Location ID | Number Sold |
1 | 1 | 10 |
1 | 3 | 6 |
2 | 1 | 5 |
2 | 2 | 22 |
Represent the above into 3-D format, focussing majorly on product-id and sales
Answer:
Product ID | Location ID | Total Sold | ||
1 | 10 | - | 6 | 16 |
2 | 5 | 22 | - | 27 |
Total | 15 | 22 | 6 | 43 |
What is a OLAP cube?
Answer:
An OLAP data cube is a representation of data in multiple dimensions, using facts and dimensions. It is characterized by the combination of information according to it’s relationship. It can consist in a collection of 0 to many dimensions, representing specific data.
There are five basic operation to perform on these kind of data cubes:
- Slicing
- Dicing
- Roll-Up
- Drill-Up
- Drill-Down
- Pivoting
Question
Why is dimensional normalization not required?
Answer:
Answer:
Dimensional normalization allows to solve database related problems. It is used to remove unnecessary features which are used as De-normalized dimensions. Dimensions have sub-dimensions which are added together. Due to this fact dimensional generalization is not used:
- Data structure is more complex and which can cause performance to be degraded because it needs to be included in tables and relationships are retained
- Query Performance suffers while collecting or retrieving multiple dimensional values It requires proper analysis and operational reports.
- Space is not used properly and more space is needed.
Question.
What are the steps involved in creating dimensional modeling process?
Answer:
The business process of the dimensional modeling includes:
(a) Choose The Business Process: In this, 4-step design method is followed that helps to provide the usability of the dimensional model. This allows the business process to be more systematic in representation and more helpful in explaining it as well. It includes the use of Business Process Modelling Notation (BPMN) or Unified Modelling Language (UML).
(b)Declaring The Grain: After choosing the business process, the declaration of the model comes that consists of grains. The grain of the model provides the accurate description of the dimensional model and allows the focus should be shifted there.
(c)Identify The Dimensions:In this phase, the dimension is identified in the dimensional model. Dimensions are defined in cereals which are defined in the declaration part above. Dimensions acts as a foundation of the fact table where the data gets collected that comes under the fact.
(d) Identify The Facts: Defining the dimensions provides a way to create a table in which the fact data can be stored. These facts are populated on the basis of the numerical figures and facts.
Question.
Consider a data warehouse, where the fact data is calculated to be 36GB of data per year, and 4 years’ worth of data are to be kept online. The data is to be partitioned by month and four concurrent queries are to be allowed.
Compute the partition size, Temporary Space and Space Required for this scenario.
Compute the partition size, Temporary Space and Space Required for this scenario.
Answer:
Partition size P = 36GB per year / 12 = 3 GB
T = (2n +1)P = [(2 x 4) + 1]3 = 27 GB
F = 36GB X 4 years = 144 GB
Space Required = 3.5F + T = 3.5 X 144 + 27 = 531 GB
T = (2n +1)P = [(2 x 4) + 1]3 = 27 GB
F = 36GB X 4 years = 144 GB
Space Required = 3.5F + T = 3.5 X 144 + 27 = 531 GB
Question.
Discuss the merits and demerits of using views from the perspective of security of data warehouse.
Answer:
Views are easier option to define security initially. Later it will cause challenges.
Some of the common restrictions that may apply to the handling of views are:
Some of the common restrictions that may apply to the handling of views are:
- restricted data manipulation language (DML) operations,
- lost query optimization paths,
- restrictions on parallel processing of view projections.
The use of views to enforce security will impose a maintenance overhead. In particular, if views are used to enforce restricted access to data tables and aggregations, as these changes, the views may also change.
Question.
For following statements, indicate True or False with proper justification:
A. It is a good practice to drop the indexes before the initial load.
True. Index entry creations during mass loads can be too time-consuming. So drop the indexes prior to the loads to make the loads go quicker. You may rebuild or regenerate the indexes when the loads are complete
B. The choice of index type depends on cardinality.
True. Bit-map index can be used only for low cardinality data
C. The importance of metadata is the same for data warehouse and an operational system.
False. In an operational system, users get information thru predefined screens and reports. In DW, users seek information thru ad-hoc queries.
D. Backing up the data warehouse is not necessary because you can recover data from the source systems.
False. Information in DW is accumulated over long periods and elaborately preprocessed
E. MPP is a shared-memory parallel hardware configuration.
False. MPP is a share-nothing hardware architecture.
False. MPP is a share-nothing hardware architecture.


No comments:
Post a Comment